import IPython
from fasttrackpy import process_audio_file, \
process_directory, \
process_audio_textgrid,\
process_corpus
from pathlib import PathPythonic Use
Here, we’ll outline how to use fasttrackpy functions and classes either in an interactive notebook, or within your own package.
Function use
The easiest way to start using fasttrackpy directly will be by calling one of the process_* functions, which will either return a single CandidateTracks object, or a list of CandidateTracks objects.
Process an audio file
You can process an audio file, and adjust the relevant settings with process_audio().
audio_path = Path("..", "assets", "audio", "ay.wav")
IPython.display.Audio(audio_path)candidates = process_audio_file(
path=audio_path,
min_max_formant=3000,
max_max_formant=6000
)Inspecting the candidates object.
There are a few key attributes you can get from the candidates object, including
- The error terms for each smooth.
- The winning candidate
candidates.smooth_errorsarray([0.22544256, 0.25078883, 0.18968704, 0.14313632, 0.13567622,
0.11614815, 0.11945207, 0.03664588, 0.03567658, 0.05305987,
0.06046965, 0.07819208, 0.10361329, 0.07013581, 0.05866597,
0.0394219 , 0.02852071, 0.05098306, 0.03279 , 0.03167985])candidates.winnerA formant track object. (4, 385)Inspecting the candidates.winner object
The candidates.winner object has a few useful attributes to access as well, including the maximum formant.
candidates.winner.maximum_formantnp.float64(5526.315789473684)Data output - Spectrograms
You can get a spectrogram plot out of either the candidates.winner or the candidates itself.
candidates.winner.spectrogram()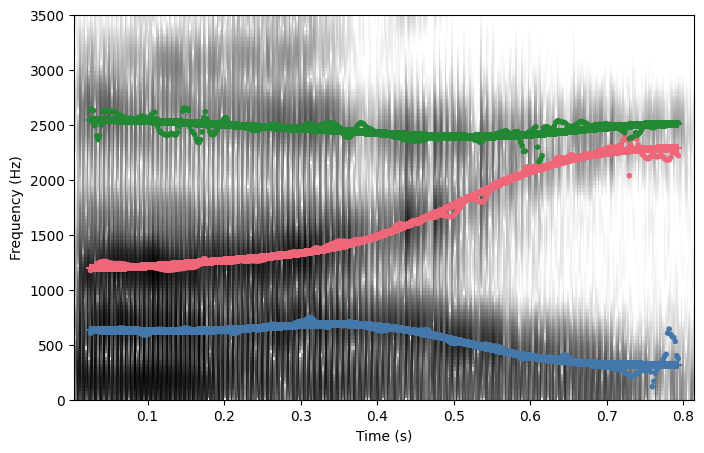
candidates.spectrograms()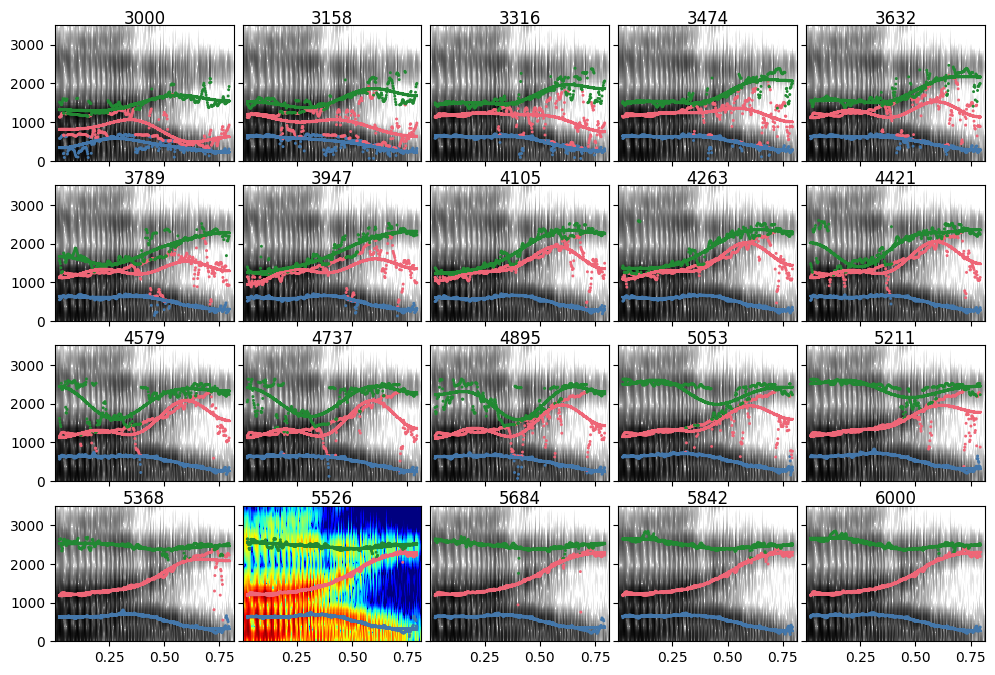
Data Output - DataFrames
You can output the candidates to a polars dataframe.
candidates.to_df(which = "winner").head()
shape: (5, 22)
| F1 | F2 | F3 | F4 | F1_s | F2_s | F3_s | F4_s | B1 | B2 | B3 | B4 | error | time | max_formant | n_formant | smooth_method | file_name | f0 | f0_s | intensity | intensity_s |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | f64 | i32 | str | str | f64 | f64 | f64 | f64 |
| 604.374108 | 1175.26731 | 2636.119643 | 2820.424313 | 631.116096 | 1196.387362 | 2542.421732 | 2978.273932 | 250.189519 | 92.942056 | 292.110777 | 797.16362 | 0.028521 | 0.025406 | 5526.315789 | 4 | "dct_smooth_regression" | "ay.wav" | 186.51622 | 177.20457 | NaN | 75.36627 |
| 613.663049 | 1183.807981 | 2638.781798 | 2764.336825 | 631.108164 | 1196.413506 | 2542.406271 | 2978.173053 | 250.177347 | 92.935681 | 292.228197 | 797.053295 | 0.028521 | 0.027406 | 5526.315789 | 4 | "dct_smooth_regression" | "ay.wav" | 185.166807 | 177.197633 | NaN | 75.366636 |
| 620.821348 | 1196.465294 | 2629.617697 | 2645.793985 | 631.09232 | 1196.465775 | 2542.375357 | 2977.971503 | 250.153031 | 92.922935 | 292.463006 | 796.832788 | 0.028521 | 0.029406 | 5526.315789 | 4 | "dct_smooth_regression" | "ay.wav" | 183.693105 | 177.183762 | NaN | 75.367367 |
| 627.364908 | 1212.220604 | 2490.175081 | 2648.947744 | 631.068604 | 1196.544133 | 2542.329008 | 2977.669702 | 250.116629 | 92.903827 | 292.815137 | 796.502384 | 0.028521 | 0.031406 | 5526.315789 | 4 | "dct_smooth_regression" | "ay.wav" | 182.223072 | 177.162963 | NaN | 75.36846 |
| 633.400922 | 1227.997019 | 2396.727652 | 2646.907343 | 631.037077 | 1196.648522 | 2542.267248 | 2977.268279 | 250.068224 | 92.878371 | 293.284494 | 796.062508 | 0.028521 | 0.033406 | 5526.315789 | 4 | "dct_smooth_regression" | "ay.wav" | 180.865837 | 177.135247 | 74.943119 | 75.369914 |
Processing an Audio + TextGrid combination.
To process a combination of an audio + textgrid, you can use the process_audio_textgrid() function. There are a few more options to add here related to textgrid processing.
TextGrid Processing
entry_classes
fasttrackpy uses aligned-textgrid to process TextGrids. By default, it will assume your textgrid is formatted as the output of forced alignment with a Word and Phone tier. If your textgrid doesn’t have these tiers, you can pass entry_classes [SequenceInterval] instead.
target_tier
You need to lest process_audio_textgrid() know which tier(s) to process, either by telling it which entry class to target (defaults to "Phone") or by the name of the tier.
target_labels
To process only specific textgrid intervals (say, the vowels), you can pass target_labels a regex string that will match the labels of intervals.
Running the processing
speaker_audio = Path("..", "assets" , "corpus", "josef-fruehwald_speaker.wav")
speaker_textgrid = Path("..", "assets", "corpus", "josef-fruehwald_speaker.TextGrid")all_vowels = process_audio_textgrid(
audio_path=speaker_audio,
textgrid_path=speaker_textgrid,
entry_classes=["Word", "Phone"],
target_tier="Phone",
# just stressed vowels
target_labels="[AEIOU].1",
min_duration=0.05,
min_max_formant=3000,
max_max_formant=6000,
n_formants=4
)100%|██████████| 174/174 [00:01<00:00, 113.19it/s]Inspecting the results
The all_vowels object is a list of CandidateTracks. Each candidate track object has the same attributes discussed above, but a few additional values added from the textgrid interval.
The SequenceInterval object
You can access the aligned-textgrid.SequenceInterval itself, and its related attributes.
all_vowels[0].interval.label'AY1'all_vowels[0].interval.fol.label'K'all_vowels[0].interval.inword.label'strikes'Labels & Ids
Interval properties also get added to the CandidateTracks object itself, including .label, which contains the interval label, and .id, which contains a unique id for the interval within the textgrid.
[all_vowels[0].label,
all_vowels[0].id]['AY1', '0-0-4-3']Outputting to a dataframe.
In order to output the results to one large dataframe. You’ll have to use polars.concat().
import polars as pl
import plotly.express as px
all_df = [vowel.to_df() for vowel in all_vowels]
big_df = pl.concat(all_df, how="diagonal")big_df.shape(8012, 25)max_formants = big_df\
.group_by(["id", "label"])\
.agg(
pl.col("max_formant").mean()
)fig = px.violin(max_formants, y = "max_formant", points="all")
fig.show()Processing a corpus
To process all audio/textgrid pairs in a given directory, you can use process_corpus(), which will return a list of all CandidateTracks from the corpus.
corpus_path = Path("..", "assets" , "corpus")
all_vowels = process_corpus(corpus_path)100%|██████████| 65/65 [00:00<00:00, 190.31it/s]
100%|██████████| 273/273 [00:01<00:00, 178.40it/s]Just like processing an audio file + textgrid combination, you’ll need to use polars.concat() to get one large data frame as output. The columns file_name and group will distinguish between measurements from different files and from different speakers within the files.
big_df = pl.concat(
[cand.to_df() for cand in all_vowels],
how = "diagonal"
)unique_groups = big_df \
.select("file_name", "group", "id") \
.unique() \
.group_by(["file_name", "group"]) \
.len()
unique_groups
shape: (3, 3)
| file_name | group | len |
|---|---|---|
| str | str | u32 |
| "KY25A_1" | "IVR" | 49 |
| "josef-fruehwald_speaker" | "group_0" | 273 |
| "KY25A_1" | "KY25A" | 16 |
Formant tracking heuristics
There are a few pre-specified heuristics for formant tracking implemented in fasttrackpy. You can import them and pass them in a list the heuristics argument of any processing function. For example, F1_Max specifies that F1 can’t be higher than 1200 Hz. Here’s an example of using it for formant tracking.
from fasttrackpy import F1_Max
candidates = process_audio_file(
path=audio_path,
min_max_formant=3000,
max_max_formant=6000,
heuristics=[F1_Max]
)The heuristic results can be accessed from the .heuristic_error attribute of the candidates object. Candidates that pass the heuristic recieve 0, and any that violate the heurostoc recieve np.inf.
candidates.heuristic_errorsarray([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])Custom Heuristics
The F1_Max heuristic is an instance of the MinMaxHeuristic class. If you wanted to create your own custom heuristic, you can do so by creating a new instance.
from fasttrackpy import MinMaxHeuristic
## The first formant average must not be higher
## than 500 Hz.
LowF1 = MinMaxHeuristic(
edge="max",
measure="frequency",
number=1,
boundary=500
)
candidates = process_audio_file(
path=audio_path,
min_max_formant=3000,
max_max_formant=6000,
heuristics=[LowF1]
)
candidates.heuristic_errorsarray([ 0., 0., 0., 0., 0., inf, 0., inf, inf, inf, inf, inf, inf,
inf, inf, inf, inf, inf, inf, inf])